
Training my own chatGPT to make another Lord of the Rings movie
Published:
Large language models are easy to use but hard to understand. It is easy to use one, just write a prompt and it generates texts, but it doesn’t tell you how or why it works. The fastest way to understand how it works is by making the simplest (and dumbest) possible version yourself, and see at what point it starts to fail.
There is this great 2-hour video to make and train your own chatGPT model by Andrej Karparov, who cofounded and formely worked at OpenAI. This is pretty comprehensive video on how to build your own nanogpt. Thus, I gave it a shot and built a character-level GPT, a small decoder-only transformer, and trained on the screenplay of The Lord of the Rings trilogy. The point is to not produce a model that writes good dialogue; a character-level model on a few hundred thousand characters is incapable and I do not possess the computational resources of OpenAI. The point is to make a simple language model and see how far it can go before it fails.
Setup
The model architecture is standard, it uses token and positional embeddings, a stack of transformer blocks with multi-head self-attention based on Karparov’s video. The corpus is small with about 424K characters and the tokenisation is only at the character level, so the model only predicts one character at a time over a voculabulary of 85 symbols. A more complex model would be to do tokenisation for words, which would make it better at spelling and generate more coherent dialogue.
I trained the model using a RTX 4060 graphics card, where the training can take about 20 minutes. After training the model, I generated some text using my model and this is the result:
ARAGORN Hise…folk who my rove be the hird of the olck skrags in priesol.
SHELOB Notheshale, where answ.
CARADIEL (V.O.) You ^out doo enument be jurn the enved foormunt of the gethe Great Fare Conle the charg.
Wizards the city cram are buuts fick inter his legoing daspsed wharf nearly thire’s you fewer are duansuapsay.
QE ON:
Aru gasps, the stilled board are danglangwrapps down a by kneess than in…cat be and before so Pool.”
FRODO (cont’d) (the voice)ing) There is nothing is me..aldere you so childe, and I willl never if this has held suckled.
Galadriel gets back away.
GANDALF He walkes bing slobJut the bbeast of Frodo’s lapshed. No, Frodo, Sam, Frodo…nic I smeagol..it’s a Ridd sove forestle.
FRODO (quietly) Here’as lvoice.
Wow, this is pretty bad. Not only the dialogue is incoherent, most words are spelt incorrectly. Okay, so what went wrong?
Overfitting
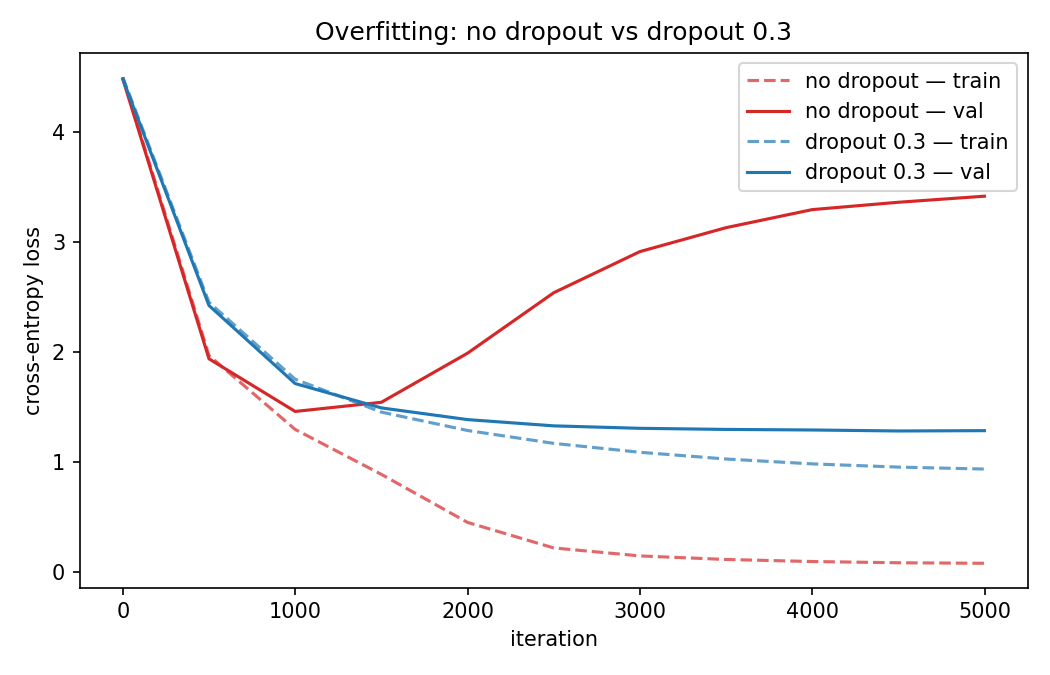
The baseline model has about 5 million parameters. Train it on 424K characters and the training loss falls toward zero while the validation loss reach its lowest and then starts climbing. The model isn’t learning the language of the script any more, it is memorising the training data. The clearest way to see this is to compare a run with no regularisation against one with dropout
Not enough data?
To figure out if the model is too big for the data, I made four different model sizes, 127k, 846k, 484M, 14M parameters, while keeping everything else constant. If the problem is data, validation loss should stop improving past a some point, where the model has enough capacity to fit everything the 424k characters can teach, and extra parameters add nothing useful.
In this plot, I show the cross entropy loss versus the number of parameters for the training and validation. Additionally, I plotted the best validation loss and also the final validation loss after 5000 iterations. We see that the best validation loss improves from 1.7 to 1.3 at ~5M parameters and staying flat at ~14M parameters. The final validation loss shows over-training as it blows up to 2.16. 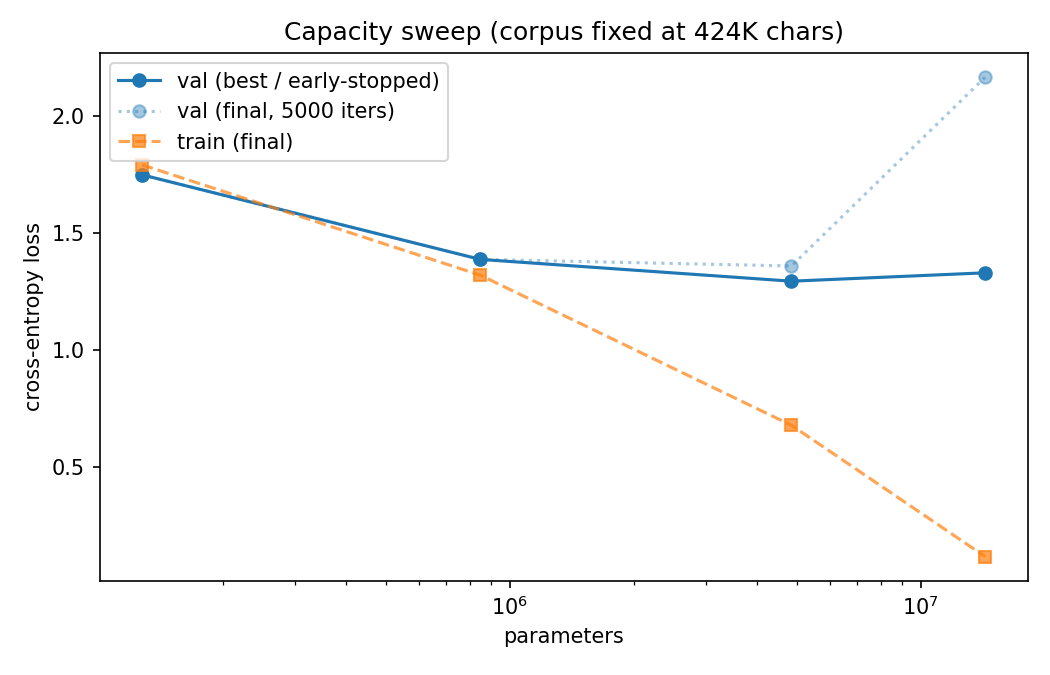
The difference between the best validation loss and final validation loss reveals that past 5M parameters, the model does not improve but actively get worse. Hence, adding capacity to our model buys nothing, as the constraint is the 424K character training set, not the size of the network. This shows that the importance of having large datasets to train on, and why frontier labs use such large datasets to train their large language models.
You can see the same effect unfold during training per model size in this plot. 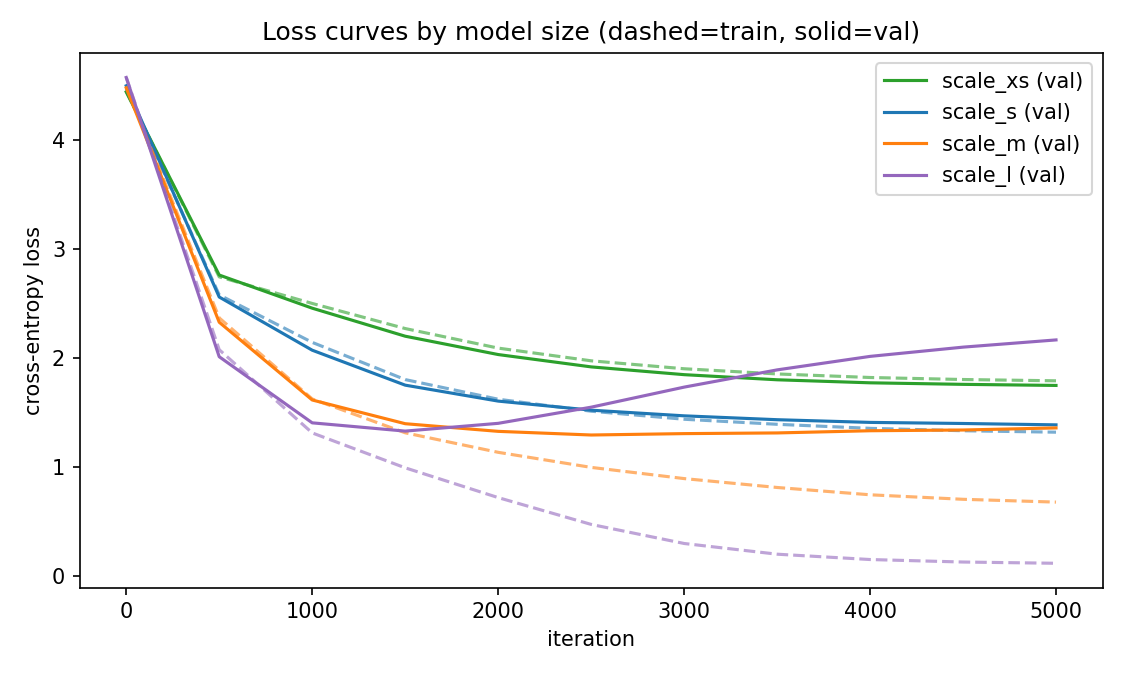
It seems that the first bottleneck in my language model is that my dataset is insufficiently big, not due to the size of my neural network. I am pretty surprised.
Regularisation
I applied regularisation to the model to reduce the overfitting. In order to figure out how much regularisation to apply, I swept the dropout value from 0 to 0.3, crossed with two weight-decy settings, and measured the final validation loss and difference between training and validation loss. 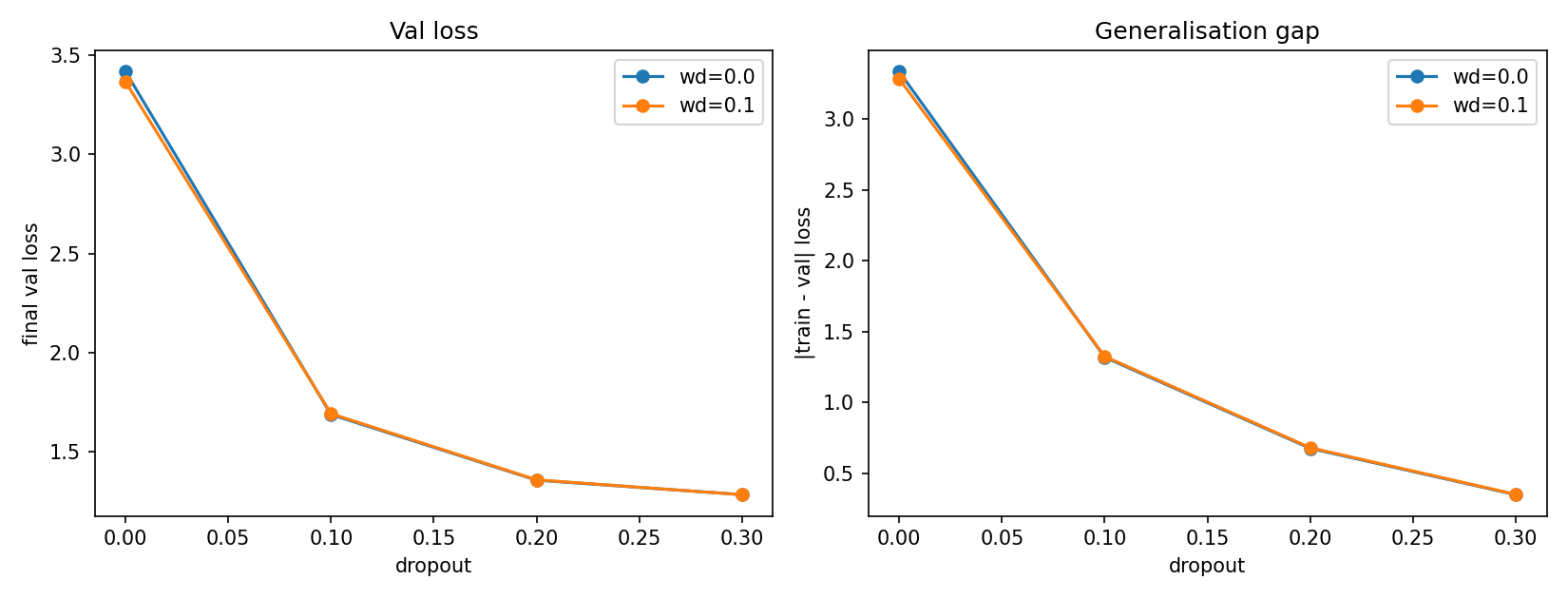
We see that the dropout is very effective and the weight decay barely affected the results.
Conclusion
The effectivenss of a language model depends on both the capacity of the model and the amount of data you train it on. Without having a sufficiently large model and a sufficiently large dataset, it is very to make a useful large language model. At both the model size and dataset scale, the computational resources required to make a language model scales. I guess this is why OpenAI and Anthropic require so much funding to sustain their large language models.